Como comenté en el artículo anterior, tuve la oportunidad de tener cierto contacto con el sistema utilizado por la empresa Magic Software Argentina (MSA) en el escrutinio provisorio de las elecciones municipales de mi ciudad, Río Cuarto.
Los fiscales informáticos tuvimos acceso a la interfaz de consulta del proceso de escrutinio y a un volcado de la base de datos, que se realizaba cada 5 minutos. Lamentablemente, no tuvimos acceso al código fuente de la aplicación (aunque espero poder acceder al informe de los peritos contratados por la Junta Electoral).
Una vez finalizado el escrutinio provisorio, surgieron diferencias en los totales de votantes de los dos cargos electivos. A raíz de esto, decidí inspeccionar la base de datos con el objetivo de generar el listado de las mesas en las cuales se originaba dicha diferencia. De dicho análisis resultó el siguiente artículo, en el que me permito realizar algunas críticas.
El diagrama de Entidad-Relación (DER)
El siguiente es el DER que nos envió la gente de MSA:
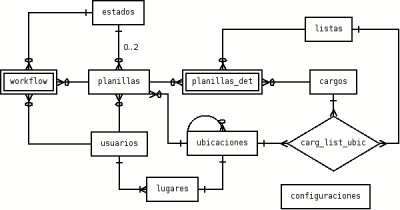
Como puede verse se trata de una base de datos realmente simple (apenas 11 tablas). Lo que me llamó la atención a primera vista fue la utilización de palabras en castellano (muchos programadores opinamos que los programas deberían estar documentados en inglés). Siguiendo con los nombres, por más que me esforcé no pude imaginar la diferencia entre «ubicaciones» y «lugares«. No encontré palabras como «mesa«, «escuela«, «circuito«. A mi entender, la elección de la nomenclatura no ha sido la mejor.
Las claves primarias
En 9 tablas de la base de datos, las claves primarias son del tipo «varchar«. Si bien esto no es del todo incorrecto, no es muy recomendable. Las claves primarias deberían ser del tipo «integer«, y además auto-incrementadas (PostgreSQL, el RDBMS utilizado, lo soporta). Esto no solamente simplifica la asignación de valores a las claves (no hay que verificar la unicidad), sino que tiene un gran impacto en el desempeño de la base de datos.
Al utilizar el tipo «varchar«, cuya longitud es variable, el tamaño de los índices es mayor que usando «integer«. Esto, al aumentar la cantidad de filas de las tablas, se torna cada vez más importante (es deseable que los índices quepan en la caché del RDBMS). (En Río Cuarto había solamente 352 mesas y menos de 110.000 votantes, por lo cual no debe haberse notado la diferencia, pero en una elección más amplia seguramente lo haría.)
Un factor que agrava la situación es que la comparación de claves, al tratarse de cadenas, debe hacerse caracter a caracter (a diferencia de la comparación de valores enteros, que se realiza mediante una simple resta). Como veremos más adelante, en algunas tablas los valores del atributo clave en varias filas tienen un prefijo en común. Esto ralentiza aún más la comparación, y la situación es empeorada por la utlización de la codificación de caracteres UTF-8, debido a la implementación interna de PostgreSQL.
En mi opinión pudiendo usar valores enteros como clave, debieron haberlo hecho.
¿Relación inexistente?
Primero, una breve explicación del problema: La ciudad se divide en 3 circuitos electorales, en los cuales se encuentran las distintas escuelas, en donde a su vez están las mesas de votación. Como el sistema permite analizar circuitos, escuelas y mesas por separado, el primer diseño que cualquier programador pensaría es disponer de tres tablas: «circuitos», «escuelas» y «mesas» (en el caso de una elección provincial o nacional se agregarían algunas más). Entre esas tablas habría relaciones 1:N, es decir «1 circuito tiene N escuelas, 1 escuela pertenece a un circuito», «1 escuela tiene N mesas, 1 mesa pertenece a 1 escuela».
Aprovechando el hecho de que tanto las escuelas como las mesas tienen los mismos atributos, decidieron usar una única tabla, denominada «ubicaciones», según muestra el DER:
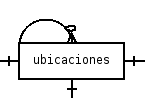
Es común utilizar este tipo de representación para estructuras de «árbol». Esto se logra agregando como atributo una clave foránea que referencia a la clave primaria de la misma tabla. En las filas «padre» dicho atributo tiene el valor «NULL«, en tanto que en las filas «hijas», dicho atributo contiene el valor de la clave primaria del padre.
Sin embargo, el código SQL de la estructura de la tabla «ubicaciones» es el siguiente:
CREATE TABLE ubicaciones ( id_ubicacion character varying(12) NOT NULL, clase character varying(30) NOT NULL, descripcion character varying(100), sexo character(1), CONSTRAINT ubicaciones_sexo_check CHECK (((sexo = 'F'::bpchar) OR (sexo = 'M'::bpchar))) );
No existe ningún atributo que oficie de clave foránea para representar la relación en cuestión. ¿Cómo es esto posible?
Para comprender cómo está representada esta relación, fue necesario analizar los datos de la tabla (algo que, después de discutirlo con varios amigos, no pudimos llegar a la conclusión de qué principios de la teoría de bases de datos violenta, quizás algún lector pueda echar algo de luz al respecto). Encontre lo siguiente:
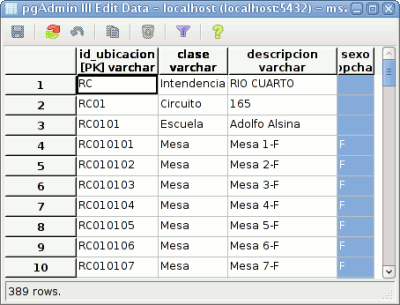
El «truco» consiste en utilizar parte de la clave primaria de una fila, para referenciar a la fila «padre». Por ejemplo, las claves de todas las mesas pertenecientes a la escuela «Adolfo Alsina» (cuya clave es «RC0101«) comienzan con el prefijo «RC0101«. De la misma manera, las claves de todas las escuelas del circuito «165» (cuya clave es «RC01«) comienzan con el prefijo «RC01«.
Ingenioso, pero totalmente innecesario y contrario a la teoría de bases de datos relacionales. De hecho, la relación está presente en el DER, pero no se ve reflejada en la base de datos. (Este tipo de representación de relaciones basadas en códigos era una práctica común de los programadores Cobol de otras épocas.)
Tipos de datos
Siguiendo con la tabla «ubicaciones«, podemos apreciar la siguiente restricción de integridad:
CONSTRAINT ubicaciones_sexo_check CHECK (((sexo = 'F'::bpchar) OR (sexo = 'M'::bpchar)))
El objetivo de esta restricción es verificar que el valor del atributo «sexo» (de tipo «character(1)» sea «F» o «M«. Una forma más simple y eficiente, es definir un tipo de datos enumerado:
CREATE TYPE sexos AS ENUM ('F', 'M')
Esta misma situación se produce en otras tablas, incluyendo la reiteración de casos como el que sigue:
CONSTRAINT usuarios_carga_check CHECK (carga = 'SI'::bpchar OR carga = 'NO'::bpchar)
Aquí, evidentemente, hubiera bastado definir al atributo «carga» de tipo «boolean«. (Esta restricción se encuentra en la tabla «usuarios«, en donde es reiterada tres veces.)
La tabla «estados» contiene los distintos estados en que puede encontrarse una planilla a lo largo del proceso:
CREATE TABLE estados ( id_estado character varying(16) NOT NULL, descripcion character varying(50), bg_color1 character varying(7), bg_color2 character varying(7), prioridad integer, orden integer, accion character varying(20), CONSTRAINT estados_id_estado_check CHECK ((((((id_estado)::text = 'Espera'::text) OR ((id_estado)::text = 'En Proceso'::text)) OR ((id_estado)::text = 'Intranet'::text)) OR ((id_estado)::text = 'Internet'::text))) );
Aquí la restricción de integridad tiene como objetivo que restringir los valores de la clave «id_estado«, pero esto deja sólo cuatro posibilidades (de hecho, ¡los cuatro estados posibles de una planilla!). Codificar en el esquema de la base de datos los valores (fijos) de las claves de las cuatro entradas que luego tendrá la tabla no parece una buena idea. (Nuevamente, de juzgarse necesario, debería haberse utilizado un tipo enumerado.)
Otro punto cuestionable es la elección de los valores para codificar cada estado: varias palabras, uso de mayúsculas y minúsculas.
Otros errores
En el DER puede verse lo siguiente:
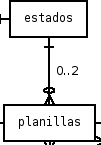
Esto parece indicar que no puede haber más de 2 planillas en el mismo estado, algo que es falso (de hecho, inicialmente todas las planillas están en el estado «Espera» y al finalizar están en el estado «Internet».
El DER también muestra la siguiente entidad:

La tabla que se corresponde con dicha entidad se llama «configuracion» (en singular).
Estos errores pueden parecer simples detalles (de hecho, en un sistema con solamente 11 tablas posiblemente lo sean), pero en un sistema más complejo pueden dificultar sensiblemente la programación, propendiendo a la comisión de errores.
Conclusión
Sin ser un experto en bases de datos relacionales (las utilizo desde hace más de 10 años como parte de mi trabajo, pero no me considero un especialista en la materia), los errores detectados me dan la pauta de que no se ha puesto el suficiente cuidado en el diseño de la base de datos, fundamentalmente de cara a la escalabilidad del sistema para soportar volumenes de carga mayores a los generados por proceso electoral como el de Río Cuarto (2 cargos electivos, 6 listas y 352 mesas).
De más está decirlo, dejo abierto este espacio a críticas y sugerencias respecto de este tema.
Muy bueno Javier! Una pregunta, esta empresa MSA es conocida, tiene trayectoria? Porque por lo que contás, parecería que fue algo que se armó a las apuradas, seguramente en connivencia con algún miembro de la junta electoral que se llevó una tajada.
Es evidente que esta aplicación fue armada de un día para otro, y diseñada y programada por principiantes, lo que no es coherente ni con el precio cobrado ni con la importancia que tiene un sistema de esta naturaleza.
Fantástico! Siempre hacen falta ejemplos de pésimo diseño para ejemplificar a los alumnos de primer año en tópicos centrales (y elementales) como la integridad referencial. Sólo necesitaría que consiguieses el código fuente y tengo para una clase perfecta.
Javier,
Quiero «echar LUZ» al tema de base de datos. Se usa para «representar arboles» en una sola tabla. No violenta ninguna regla de Base de Datos. Solo el del sentido común: usar algo, con un destino para el cual no fué diseñado. Por ejemplo, algo asi como: «usar un clavo para martillar».
Respecto del «Truco» de Usar ÁRBOLES en la tabla ubicaciones. Conozco el truco en el peor sistema de contabilidad que he visto, en COBOL. El truco es usado, para cuentas contables, para determinar en una muy limitada representación de una estructura de «árbol» la relación Padre, hijo o Madre, hija en un «ilimitado» manejo de subniveles en el plan de cuentas y todo en una sola tabla. El truco es ingenioso. Pero totalmente inapropiado.
Saludos,
gab
Javier,
La nota no es muy buena. Es EXCELENTE!.
Tengo que felicitar tu vocación de educarnos a todos. Tu nota me educa, me anoto en primera fila.
Tu BLOG en general es de una CALIDAD envidiable. Es casi Perfecto.
Pero lo que quiero decir algo que NO ESTA QUEDANDO CLARO para el público en general, y lo digo, porque al principio yo tampoco lo tenía claro, con tu nota de ayer y mas con la de hoy se me aclaró por completo, pero que no podía entender debido a la tremenda incoherencia de lo sucedido, y eso es:
El sistema de Escrutinio de 352 MESAS, es un sistema que tiene menor complejidad que un sistema completo para un KIOSCO, que nunca superaría los, digamos 3000 pesos?. Bueno, el punto es, que uno piensa en los 110.000 votantes, pero esos votantes, no son ninguna complicación, ni medida del volumen de datos a manejar, ya que podrían ser 10 veces mas votantes, y sin embargo no complicar el sistema en el mismo grado. El volumen de datos mas importante, son esas 352 MESAS, nada mas.
Sólo los 352 registros son los que estarán en la tabla más GRANDE de todo el sistema. o sea NADA, la complejidad de ese sistema se puede resolver en el VISICALC corriendo en la Apple II, ambos de 1982, que tenía la capacidad para 1024 registros. En ese sistema, quedo demostrado, la operación mas complicada a realizar es la SUMA.
Saludos,
gab
Qué es eso!??! .Qué manera de complicarse no solo con las entidades lugares y ubicaciones, sino con la entidad configuraciones!
Vaya a saber que tipo de normalización tienen las tablas!
Nunca tendrán consistencia los datos con una base de datos así, y menos obtener resultados correctos. Me asombra.
Ni siquiera esta implementada para manipular datos con algún fin. Qué peligroso seria el voto electrónico con gente así. :(
Muy bien explicado todo… En su día tuve que programar una aplicación web para gestionar unas elecciones municipales con PHP+MySQL y pasé un montón de horas revisando las tablas y sus relaciones.
Respecto al tema de las mesas electorales lo suyo es una tabla para distritos (o circuitos) electorales, otra para colegios y otra para las mesas. Como bien dices se puede utilizar una estructura en árbol, pero este tipo de soluciones es para casos en los que es imposible determinar un número de hijos o ramificaciones (como puede ser un foro o unas news, que no se puede determinar ni limitar el número de respuestas que va a tener un hilo). Además, en el caso concreto de unas elecciones, estamos hablando de como mucho unas 7 tablas para determinar la localización de una mesa: Estado o Comunidad Autónoma, Provincia, Localidad, Distrito, Colegio y Mesa. Lo que aunque parece mucho simplifica mucho la lógica de la aplicación.
Para mi el utilizar un sistema de árbol o el utilizado en el caso que comentas es un error muy gordo: simplifica la base de datos, si, pero a un precio muy alto al complicar excesivamente la logica de la aplicación.
Buenas Javier,
Mi nombre es Gabriel, y trabajé en MSA durante casi doce años, hasta Julio del 2007. Mi intención no es ser el abogado de la empresa, porque supongo que si quieren escribir alguna replica lo van a hacer, sino defender el trabajo de los que participamos alguna vez en este tipo de proyectos.
En cuanto a lo que describiste en el post anterior, no puedo escribir demasiado porque ya no trabajo en la empresa y por lo tanto no participé de este proceso en particular. Tampoco puedo hablar de los temas de cuanto se pago, que se dio a cambio, con que se quedó el municipio, etc, ya que nunca estuve en el área comercial.
Vamos a lo técnico…
A menos que alguien le haya hecho algún retoque, me parece que ese DER lo hice yo, y no es precisamente la documentación del proyecto sino que fue el bosquejo de lo que deberíamos hacer para uno de los últimos proyectos en los que participé. Seguramente se coló de un documento a otro y llegó a ustedes… pero bueno, por eso algunas inconsistencias en cuanto a la realidad.
En cuanto al idioma, no me molesta documentar y leer en inglés (afortunadamente no tengo ningún problema con el idioma), pero no veo la razón para documentar en inglés si todos los desarrolladores eramos argentinos. Sinceramente, prefiero que documenten en español antes que tiren un comentario en inglés ofuscado, o no hagan ningún comentario por miedo al idioma.
Veo que se armo mucho revuelo con el tema de las claves primarias y principalmente sobre la tabla ubicaciones y su id un tanto extraño. En el equipo teníamos un DBA de Oracle (antes usábamos esa BD) sumamente competente, que seguramente se encargaba de optimizar tipos de datos, etc, por lo que solo nos dedicábamos a diseñar la solución al problema. Es lo bueno de trabajar en equipo, vos haces tu parte y el que sabe se encarga de lo suyo. Si bien los ids alfabéticos no son lo mejor, en este caso eran necesarios, y como la performance estaba dentro de lo establecido, lo mantuvimos así. (bueno, supongo que lo del varchar en una clave SI fue un descuido)
En cuanto a la tabla ubicaciones; si, podríamos haber separado en país, provincia, circuito, escuela, mesa, etc. El tema es que no todas las provincias siguen el mismo esquema ni nomenclatura. En algunas es distrito, en otras circuito, en otras usan departamentos, municipios, distritos escolares, y a veces el orden o cantidad de niveles es levemente diferente. En este caso, poner todo en una sola tabla es la solución mas practica (que encontramos) si queríamos reutilizar algo del diseño en diferentes proyectos.
El código de ubicaciones, como menciona Gabriel Medina, esta basado en el modelo jerárquico o de arboles que comúnmente se utiliza en sistemas contables, pero no por esto hay que despreciarlos, el objetivo de estos códigos es minimizar consultas por un lado y facilitar la totalización de datos por el otro.
Podríamos haber representado la misma estructura usando ids enteros, y guardando un id de referencia al padre (esto sería lo primero que se le viene a uno a la mente), pero el problema sería el siguiente: dado un id en particular, para obtener todos sus ancestros tendrías que hacer n-1 queries, siendo n el nivel actual. En cambio, utilizando este tipo de códigos tenés a todos tus ids ancestros a tu disposición en todo momento, incluso podes saltar directamente al primer nivel, o al tercero, sin pasar por los otros. Seguramente esto no se visualiza a nivel intendencia como es el caso que estas mostrando, pero agregale al menos dos niveles mas (país + provincia) para unas elecciones nacionales, y ahí empieza a tener sentido.
Por otro lado, cuando se guardan los datos obtenidos de las planillas, se relacionan solo con las hojas del árbol, con el nivel mas bajo (seguramente, mesa). De esta forma es muy simple totalizar para una elección nacional o provincial (de nuevo, esto no se visualiza bien con los datos actuales).
Voy a tratar de poner un ejemplo sin extenderme demasiado:
Supongamos el escenario de una elección nacional, donde hay que mostrar totales por nación (presidente), por provincia (diputados, senadores, gobernador, presidente), por municipio/distrito/departamento/etc (intendente, concejales, + los de prov)
El código tendría al menos 5 niveles (simplificando la cosa): país + provincia + distrito + escuela + mesa, y los códigos de las hojas serian algo así: ARBA010101, ARRN010101, ARCB020533, etc
Al registrar los datos de las planillas relacionados con estos códigos se simplifica mucho las queries para totalizar. Por ejemplo, si queremos hacer la consulta de presidente a nivel nacional, haces un «sum(votos) where ubicación like ‘AR%’ » (en pseudo sql) y ya totalizaste. Si queres sabes como va para el mismo cargo, pero en Río Negro, cambias AR por ARRN: «sum(votos) where ubicación like ‘ARRN%’ «, y así para todos los niveles. ¿Se entiende la idea? Te aseguro que lo probamos bastante con bases mucho más grandes que la de Río Cuarto, y no hay problemas de performance que no pueda manejar un DBA.
Sobre los tipos de datos, no me voy a meter en el laburo del equipo actual sobre como definieron o no los constraints, pero simplemente quiero comentar que para el caso de los estados, usar un string en vez de un int como id te permite visualizar mucho más rápido el estado de las planillas: no hace falta que hagas un join, etc. Es simplemente por comodidad. Seguro que ocupa más que usar un entero, pero no eramos partidarios de optimizar por el simple hecho de optimizar. Si había una idea interesante (aunque no estuviera en los libros) se ponía a prueba. Si el resultado era el esperado, y la performance estaba dentro de los limites establecidos, adelante, sino a buscar otra cosa. Ah.. otro detalle, el sexo nunca sería boolean, porque a veces se usa para indicar mesas de extranjeros, mesas especiales, etc, y no por el sistema, sino porque viene definido así por el juzgado electoral.
Como verás, hubo algún trabajo de planificación del diseño, y te puedo asegurar que hubieron muchas pruebas, y este diseño fue mutando durante varios años en los hicimos este tipo de proyectos.
Bueno, me parece que me extendí demasiado, simplemente quería dar la opinión del otro lado, pero repito: ya no trabajo en la empresa así que no la represento, simplemente hablo desde lo técnico. Teníamos nuestros motivos para hacer las cosas de tal o cual forma, seguramente no fue puntualmente la de los libros, pero vamos… no es un poco aburrido vivir siempre apegado a los libros? ;)
Bromas aparte, me parecieron muy interesantes tus dos posts sobre el tema, y me parece que ganaste un lector. Si queres hacer alguna pregunta sobre este tema o cualquier otro, no dudes en hacerlo, estoy a tu disposición para lo que se pueda, pero repito que no soy el representante de la empresa, soy solo un colega de mas o menos la misma edad.
Gabriel (Patiño):
Agradezco mucho tu respuesta. Me encanta este tipo de discusiones, que aunque puedan ponerse muy acalorada, son racionales y con fundamentos técnicos.
Lamentablemente, por estos días estoy bastante saturado de trabajo, pero me prometo tomarme un tiempo para hacer algunas pruebas y responder a tu mensaje, para aclarar algunos puntos en los que no coincido contigo (y también resaltar aquellos en que sí coincido).
¡Muchas gracias por tu opinión!
Gabriel Patiño,
Me gusto tu participación, creo que respondiste con mucho cuidado y personalmente agradezco tu aporte, me gusta que se escuchen varias campanas, y que no haya enojos inútiles.
Con respecto a los descuidos, no deberían tomarse tan livianamente. Pero, lamentablemente muchas veces llegamos a soluciones muy sub-óptimas por tiempos, presupuesto u otras razones muy lejos de lo técnico.
De nuevo, me gusta y felicito tu participación, y estar apegado a las normas es poco creativo y a veces aburrido.
Saludos,
gab
Te molesto por una razon, me comentaron que desde el moden de fibertel se puede sacar un cable y conectar la tv, es cierto? y si es asi como se hace?
Yo lo quise conectar, pero se ven muy pocos canales, solo los del 60 en adelante, nose si es que estoy haciendo algo mal, o que?
Espero tu respuesta, desde ya mil disculpas.
Hasta luego.
PARA CONTESTAR A NATALIA SE USA UN DERIVADOR QUE SE COMPRA EN LAS CASAS DE ELECTRONICA Y PREGUNTA DE ESTA MANERA QUE BUSCAS UN DERIVADOR CON SALIDA PARA MODEM Y TV ENTONCES CONECTAS LA ENTRADA AL DERIVADOR Y TENES LAS 2 SALIDAS QUE BUSCAS UNA PARA TV Y OTRA PARA MODEM
Creo que actualmente un SGBD debería ser capaz de tener en cuenta las optimizaciones pertinentes para que no hubiera (casi) diferencia en el uso de claves primarias numéricas o alfanúmericas. Considero que es una tarea de bajo nivel propia del SGBD. Por eso no veo mal el planteamiento aunque luego según la tecnología utilizada se realicen optimizaciones manuales.
Además el uso de cadenas como claves permite dotarlas de contenido semántico evitando en algunos casos joins que de la otra forma quedan como obligatorios.
Por otra parte, me gustaría cuando tuvieses tiempo, extendieras tu explicación (dieras tus razones) sobre por qué usar el inglés para poner nombres.
Un saludo.
Supongo que la respuesta de Javier será similar a la mía. Todos los nombres y comentarios en el código fuente de un sistema deberían estar en inglés, porque nunca se sabe donde va a terminar el sistema. Y si mañana vienen de China, o de Hungría, porque quieren usar el sistema para las elecciones de allí? Te vas a perder un excelente negocio por haber escrito todo en español, y hacerlo incomprensible para la mayoría de la gente de países de habla no hispana? Qué harías si te pasan un código fuente para que lo revises, y los nombres y comentarios estuvieran todos en Checo?
De acuerdo, llegado el caso podrías traducir todo, pero sería un trabajo bastante denso que podría haber estado resuelto desde el principio.
Guste o no, el inglés es el idioma universal de este mundo globalizado, siempre hay alguien que lo entiende en cualquier lugar del mundo. Y cualquier persona que trabaje en el ámbito de la informática, debería tener al menos un conocimiento medio de inglés, quienes no lo tienen ven como se les cierran muchas puertas en la cara.
hola me gustaria esta bueno el documento…me gustaria sabr si no tienen una base de datos para una escuela donde se tendra tablas como alumnos, docentes, ect.. y se llevara el control de las asistencia promedios es para mi tesis si tiene algo mandanme a mi correo gracias y les digo algo esta documento lo lei y sivio mucho
Hola javier.
Con respescto al diseño de las bases de datos es un desastre. no puedo entender como ese esquema le llevo años desarrollarlo. para el caso de los tipos enumerados se les ocurrio crear «check» , ya que estaban le hubieran agregado un modulo en Assembler. por favor no invetemos la polvora.
Que no se confunda el concepto clave con clave primaria, la clave primaria es mas eficiente con un integer porque compararla solo requiere un if, ocupa pocos bytes y ademas su longitud es constante. ocupa menos espacio en el indice y memoria y es mucho mas rapido que las VARCHAR. que la comparacion se hace letra a letra.
por favor que no se discuta esto se que ha muchos que ingnorar un buen diseño de db les encanta jugar con nombres pero para las db los numeros son mejores indudablemente.
En cuanto al modelo DER se supone que modela logicamente aspecto de la realidad de nuestro sistema. entonces porque se agregan esos atributos con sufijos o sea se esta salteando el modelado de la relacion padre. Me imagino los nuevos numeros de documentos COMO PREFIJO LOS DNI DE NUESTROS PADRES Y LUEGOS LOS NUESTROS. Se imaginan la cantidad de numeros que tendran nuestros nietos y la futuras generaciones.
Saludos.:
no mal …. recontra pesimo
Hola , queria felicitarte, pues tu pagina es exelente
te mando un abrazo .
Vi su artículo con cierto interés, aunque supone varias cosas que por su opinión, no es muy experto en el tema inormático, o es muy obsoleto el artículo, las nomenclaturas no tienen por que ser en ingles, las llaves primarias no es normativo que sean numéricas, es un artilugio cuando no se tiene un identificador único, además el tipo caracter es más eficiente y ocupa menos bits.